References : Why even bother about Evals? Notebook ML
Three Foundational Planes:
- Datasets
- Metrics
- Methodology
1. Define the scope and objectives
-
What is it that you want to ensure is the case when the user is interacting with your product?
-
Don’t take anything for granted
-
Leave room for unexpected behaviours Listen for unexpected use cases
-
Decompose the System: What individual steps make your system?
- Some steps are deterministic, include them especially if it is upstream. Small changes at the initial steps have a massive impact downstream.
- Some are branched, do the best heuristic of flattening out the most important parts.
-
Primary Goals: Focus on validating performance against real-world requirements and user-facing needs
Rule of thumb
- Granular evaluation means breaking the system down into smaller tasks to identify where improvements are needed
- Focus on validating performance against real-world requirements and user-facing needs
2. Evaluation Dataset Formulation
Rule of Thumb
- Your evaluation dataset must accurately reflect the complexity and diversity of the contracts your system will encounter in the real world
- Human-Annotated Golden Datasets are the preferable method of curation
| Steps | Application to Contract Extraction Project |
|---|---|
| Defined Scope | Ensure the dataset aligns with the specific extraction tasks (e.g., extracting dates, party names, jurisdiction clauses). Create tailored datasets for individual system components (e.g., document pre-processing, data extraction module). |
| Demonstrative of Production Usage | The dataset must mimic the inputs and scenarios expected from actual users, including variations in contract length, legal jargon, and layout complexities |
| Diverse | Critically, capture the variety of input file types (PDF, images, DOCX) and quality to capture the full problem space. This includes variations in formatting, scanning quality, and the diversity of legal clauses. |
| Decontaminated | Ensure the evaluation dataset is entirely separate from any data used during the LLM’s training to prevent misleadingly high performance metrics |
| Dynamic | Treat the dataset as a living body of work that evolves as real-world contract types or extraction requirements change |
- Subject Matter Experts (SMEs): Leverage in-house SMEs to reveal subtleties in what constitutes a high-quality response, such as ensuring correctness and completeness
- Metadata and Ground Truth: Beyond the prompt (the contract file), curate Ground Truth responses (the accurately extracted structured data). It is crucial to define Expected Information—specific fields, terms, or facts the model must recall in its structured output—and audit this information for correctness, as it directly impacts your metrics.
How Many Cases Do I need?
Required Evaluation Set Sample Sizes Datasets must be large enough to measure representative metrics. We can derive a rough estimate of minimal evaluation set size n required to estimate the performance of the model and adequately represent outcomes when deployed via standard statistical sample size calculation (Singh and Masuku, 2014).
n = z^2 × m(1− m)/ϵ^2. (1)
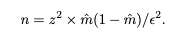
Here, z is the z-score for a chosen confidence level, m is the expected metric score (e.g., 0.8 for 80% accuracy), and ϵ is the desired margin of error. For example, to achieve 95% confidence (z=1.96) with a 5% margin of error for a metric expected to be 80%, approximately 246 samples
3. Metrics Selection (Measuring Quality)
Warning
This is actually an open field and there isn’t one sure shot way to decide which ones you should be using. Be creative and read up about error analysis techniques.
Want to work on data extraction?
- traditional text-overlap metrics like ROUGE or BLEU are insufficient or potentially misleading
- focus on metrics that verify the accuracy, presence, and adherence to the required structure
A. Deterministic and Reference-Based Metrics
Prioritise when the result you want is objective.
| Metric Category | Specific Metrics/Techniques | Rationale |
|---|---|---|
| Exact/Fuzzy Matching | Exact Match/Fuzzy Match: Compare the extracted strings (e.g., party names, effective dates) to the ground truth, allowing for minor variations like formatting. | Essential for narrow Q&A or data extraction tasks where there is one right answer. |
| Structured Data Validation | JSON Match: Verify if the output adheres to the correct syntax and that all required key-value pairs (e.g., product_name, price) are present and correct. | Confirms format adherence and field completeness, which are key requirements for structured data output. |
| Component Quality | If using Retrieval-Augmented Generation (RAG) components (e.g., extracting specific paragraphs before LLM processing), traditional retrieval metrics like Precision@k, Recall@k, or Mean Reciprocal Rank (MRR) can evaluate the quality of the intermediate output. | Measures performance of intermediate steps, helping to isolate retrieval failure modes. |
B. LLM-as-a-Judge Metrics (For Nuance and Completeness)
LLMs can serve as scalable automated raters (“auto-raters”) to assess aspects that simple programmatic checks might miss, such as overall completeness or context-aware accuracy.
-
Semantic Similarity Matching: Use a judge LLM to compare the extracted data (or the explanation derived from it) to the reference answer to determine if they convey the same meaning, style, or details. This overcomes the simple term-overlap problem associated with metrics like ROUGE.
-
Groundedness / Faithfulness: If your LLM relies on the content of the source contract, an LLM judge can verify alignment with the context and check for hallucinated or unsupported details (which would be particularly damaging in a legal context).
-
Accuracy and Completeness: A properly prompted LLM judge can evaluate response quality based on specific criteria like “factual accuracy” and “completeness”.
Crucially, when using LLM judges, you must “evaluate your evaluators” against human annotations to maintain reliability and manage biases (such as favouring verbose responses).
4. Robust Evaluation Methodology & Execution
The execution phase addresses the inherent challenges of LLM systems, such as non-determinism and sensitivity.
A. Error Analysis and Iteration
Error analysis is the most important activity in evaluations. It helps you define which evaluation metrics to prioritize by identifying failure modes unique to your contract application.
-
Manual Review: Start by manually reviewing a sample of traces (e.g., 20–50 outputs) to gather open-ended notes about issues.
-
Axial Coding: Categorize these open-ended notes into a “failure taxonomy.” Group similar issues into distinct categories (e.g., “Failure to extract date format,” “Hallucination of party name,” “Inaccurate parsing of image files”).
-
Iterative Refinement: Use these identified failure modes to build targeted automated evaluators.
B. Handling Variability
LLMs are stochastic, meaning they can produce unpredictable outputs.
• Non-Determinism: To handle variability, run the evaluation multiple times (e.g., or larger) on fixed inputs, average the results, and report the variability induced by system noise. Alternatively, use Self-Consistency, which involves sampling multiple responses and selecting the most frequent one.
• Prompt Sensitivity: Assess system sensitivity by injecting various types of noise into the input (e.g., minor changes in contract language or formatting irregularities typical of bad scans) and measuring how the structured outputs change. This helps identify instability, which is critical for an application handling sensitive documents like contracts.
C. Continuous Evaluation
Evaluation should be an iterative practice that closes the loop between offline testing and real-world data.
• Monitoring: Log interactions and curate problematic cases and feed them back into your evaluation datasets.
• Dataset Drift: Recognize that as user behavior and product requirements evolve (e.g., new types of contracts are introduced), your custom evaluation datasets must be regularly updated to catch regressions and address new failure modes.